News
📣 [11/2024] Introducing AgentQuest [COMING SOON]
Leaderboard
|
Agent
|
% Progress
|
BabyAI
|
Crafter
|
TextWorld
|
BabaIsAI
|
MiniHack
|
NetHack
|
Date
|
|---|---|---|---|---|---|---|---|---|
|
🕹️ ✔️ Qwen2.5-72B-it |
16.2 ± 1.6 |
34.0 ± 6.7 |
27.3 ± 3.6 |
11.2 ± 3.8 |
19.3 ± 3.6 |
5.0 ± 3.4 |
0.3 ± 0.3 |
2024-11-17 |
|
🥈 🕹️ ✔️ Claude-3.5-Sonnet |
30.0 ± 2.0 |
52.0 ± 7.1 |
32.7 ± 3.2 |
42.1 ± 5.4 |
37.5 ± 4.4 |
15.0 ± 5.6 |
0.6 ± 0.5 |
2024-11-11 |
|
🕹️ ✔️ Gemini-1.5-Flash |
10.6 ± 1.0 |
25.6 ± 3.9 |
20.0 ± 0.7 |
0.0 ± 0.0 |
12.8 ± 2.3 |
5.0 ± 3.5 |
0.0 ± 0.0 |
2024-11-11 |
|
🕹️ ✔️ Llama-3.1-8B-it |
14.1 ± 1.5 |
30.0 ± 6.5 |
25.5 ± 3.2 |
6.1 ± 2.4 |
18.3 ± 3.5 |
5.0 ± 3.4 |
0.0 ± 0.0 |
2024-11-11 |
|
🕹️ ✔️ Qwen-2.5-7B-it |
7.8 ± 1.1 |
14.0 ± 4.9 |
16.4 ± 3.0 |
3.9 ± 1.0 |
12.5 ± 3.0 |
0.0 ± 0.0 |
0.0 ± 0.0 |
2024-11-17 |
|
🕹️ ✔️ Qwen2-VL-7B-it |
3.7 ± 0.8 |
4.0 ± 2.8 |
6.4 ± 1.7 |
1.6 ± 0.6 |
7.6 ± 2.4 |
2.5 ± 2.5 |
0.0 ± 0.0 |
2024-11-18 |
|
🕹️ ✔️ Llama-3.2-3B-it |
8.5 ± 1.1 |
10.0 ± 4.2 |
17.3 ± 2.8 |
3.5 ± 1.1 |
17.5 ± 3.5 |
2.5 ± 2.5 |
0.0 ± 0.0 |
2024-11-11 |
|
🥇 🕹️ ✔️ GPT-4o |
32.3 ± 1.5 |
77.6 ± 3.7 |
33.1 ± 2.3 |
39.3 ± 5.2 |
33.7 ± 3.3 |
10.0 ± 4.7 |
0.4 ± 0.4 |
2024-11-11 |
|
🕹️ ✔️ Gemini-1.5-Pro |
21.0 ± 1.2 |
58.4 ± 4.4 |
30.2 ± 2.9 |
0.0 ± 0.0 |
32.0 ± 3.3 |
5.0 ± 3.5 |
0.4 ± 0.4 |
2024-11-11 |
|
🕹️ ✔️ Qwen2-VL-72B-it |
12.8 ± 1.6 |
24.0 ± 6.0 |
22.7 ± 2.7 |
16.5 ± 5.4 |
10.8 ± 2.8 |
2.5 ± 2.5 |
0.0 ± 0.0 |
2024-11-17 |
|
🥉 🕹️ ✔️ Llama-3.1-70B-it |
27.9 ± 1.4 |
73.2 ± 4.0 |
31.2 ± 2.7 |
15.0 ± 4.6 |
40.0 ± 3.4 |
7.5 ± 4.2 |
0.3 ± 0.3 |
2024-11-17 |
|
🕹️ ✔️ GPT-4o-mini |
17.4 ± 1.4 |
50.4 ± 4.5 |
15.9 ± 2.0 |
12.2 ± 3.5 |
15.6 ± 2.5 |
10.0 ± 4.7 |
0.0 ± 0.0 |
2024-11-11 |
|
🕹️ ✔️ Llama-3.2-90B-it |
24.5 ± 1.2 |
55.2 ± 4.5 |
31.7 ± 1.4 |
11.2 ± 3.0 |
43.9 ± 3.5 |
5.0 ± 3.4 |
0.0 ± 0.0 |
2024-11-11 |
|
🕹️ ✔️ Llama-3.2-11B-it |
14.0 ± 1.1 |
32.8 ± 4.2 |
26.2 ± 3.3 |
6.7 ± 2.2 |
15.6 ± 2.5 |
2.5 ± 2.5 |
0.0 ± 0.0 |
2024-11-11 |
|
🕹️ ✔️ Llama-3.2-1B-it |
6.3 ± 1.0 |
6.0 ± 3.4 |
12.7 ± 1.9 |
3.3 ± 0.9 |
10.8 ± 2.8 |
5.0 ± 3.4 |
0.0 ± 0.0 |
2024-11-11 |
|
Agent
|
% Progress
|
BabyAI
|
Crafter
|
BabaIsAI
|
MiniHack
|
NetHack
|
Date
|
|---|---|---|---|---|---|---|---|
|
🥇 🕹️ ✔️ Claude-3.5-Sonnet |
29.1 ± 2.2 |
50.0 ± 7.1 |
37.3 ± 3.1 |
34.5 ± 4.4 |
22.5 ± 6.6 |
1.2 ± 0.4 |
2024-11-11 |
|
🕹️ ✔️ Gemini-1.5-Flash |
14.9 ± 1.4 |
43.2 ± 4.4 |
20.7 ± 4.4 |
8.3 ± 1.9 |
2.5 ± 2.5 |
0.0 ± 0.0 |
2024-11-08 |
|
🕹️ ✔️ Qwen2-VL-7B-it |
4.4 ± 0.8 |
2.0 ± 2.0 |
5.5 ± 0.9 |
11.9 ± 3.0 |
5.0 ± 3.4 |
0.0 ± 0.0 |
2024-11-18 |
|
🥉 🕹️ ✔️ GPT-4o |
22.6 ± 1.4 |
62.0 ± 4.3 |
26.8 ± 3.7 |
18.6 ± 2.7 |
5.0 ± 3.4 |
0.4 ± 0.4 |
2024-11-08 |
|
🥈 🕹️ ✔️ Gemini-1.5-Pro |
25.8 ± 1.4 |
58.4 ± 4.4 |
33.5 ± 2.1 |
31.4 ± 3.2 |
5.0 ± 3.4 |
0.5 ± 0.5 |
2024-11-08 |
|
🕹️ ✔️ Qwen2-VL-72B-it |
12.2 ± 1.6 |
34.0 ± 6.7 |
18.6 ± 2.8 |
5.9 ± 2.2 |
2.5 ± 2.5 |
0.0 ± 0.0 |
2024-11-17 |
|
🕹️ ✔️ Llama-3.2-90B-it |
13.4 ± 1.2 |
28.2 ± 4.0 |
14.5 ± 1.8 |
21.9 ± 2.9 |
2.5 ± 2.5 |
0.0 ± 0.0 |
2024-11-11 |
|
🕹️ ✔️ Llama-3.2-11B-it |
6.9 ± 0.8 |
10.4 ± 2.7 |
15.9 ± 1.2 |
5.8 ± 1.6 |
2.5 ± 2.5 |
0.0 ± 0.0 |
2024-11-11 |
|
🕹️ ✔️ GPT-4o-mini |
15.4 ± 1.3 |
38.0 ± 4.3 |
19.9 ± 3.1 |
16.4 ± 2.6 |
2.5 ± 2.5 |
0.0 ± 0.0 |
2024-11-08 |
- The % Progress metric refers to the average
completion
percentage of AgentQuest
environments of the model.
- ✔️ Checked indicates that we, the AgentQuest team,
received
access to the system and
were able to reproduce the patch generations.
- 🕹️ Open refers to submissions that have
open-source
code. This
does not
necessarily mean the underlying model is open-source.
- The leaderboard is updated once a week on Monday.
- If you would like to submit your model to the leaderboard, please check the submission page.
Below we show visual examples of the environments used in AgentQuest
Crafter
BabaIsAI
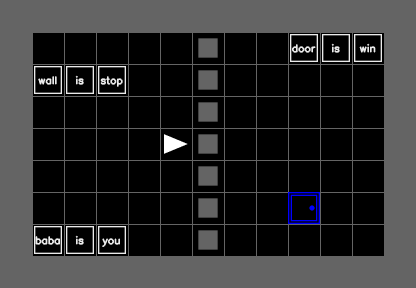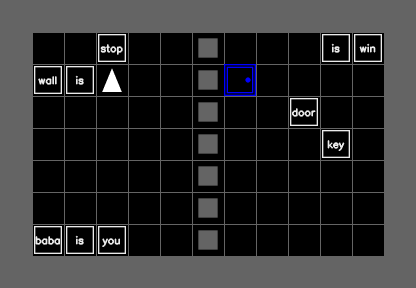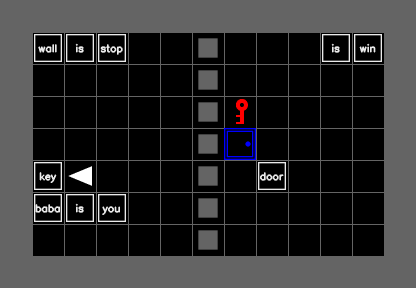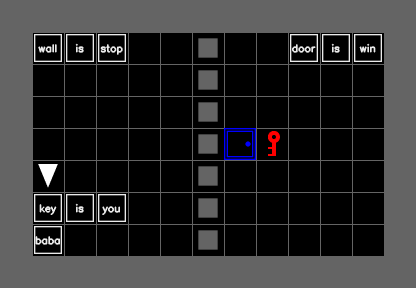
MiniHack

NetHack
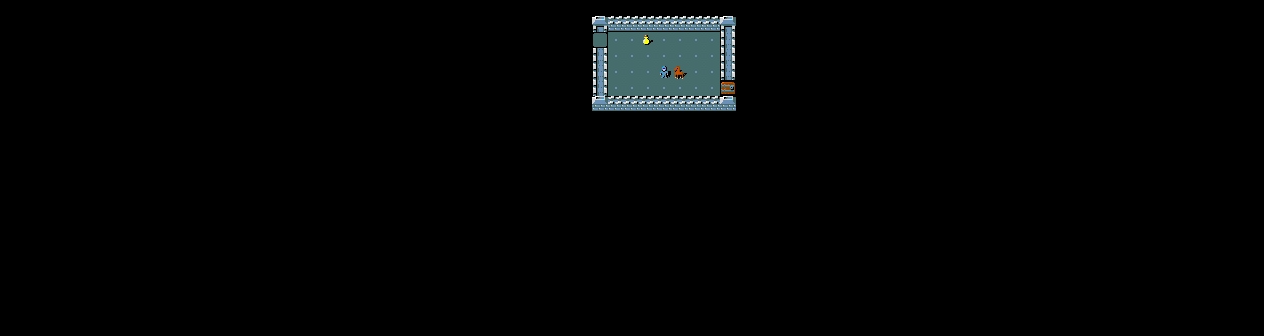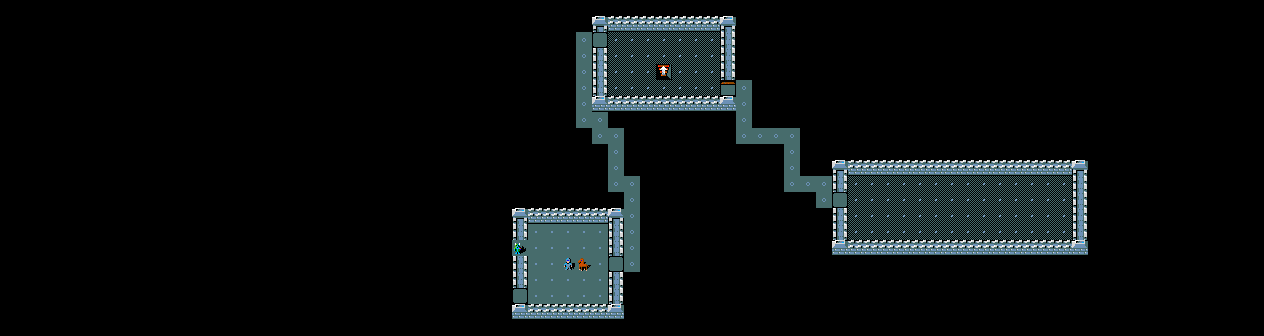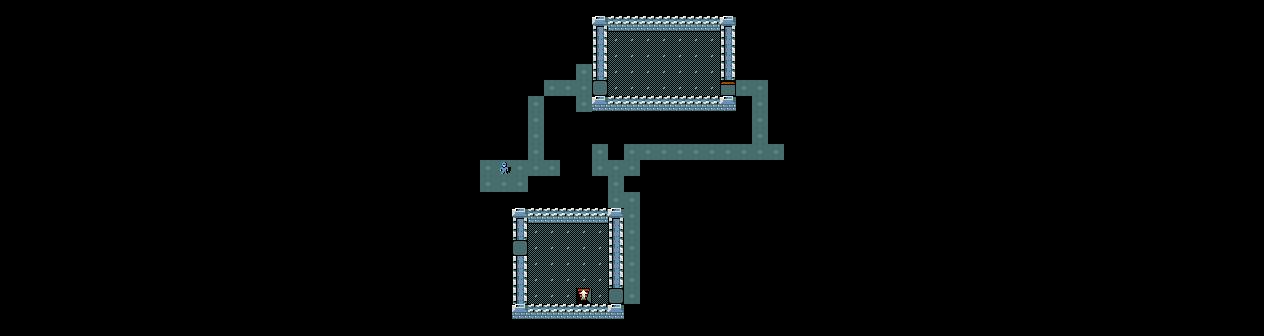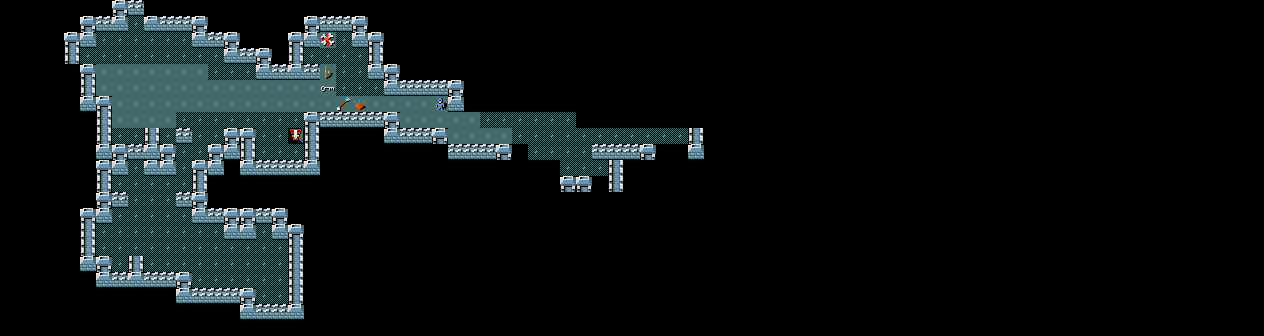
TextWorld
BabyAI

About
AgentQuest is a benchmark designed to evaluate the agentic capabilities of large language and vision-language models (LLMs and VLMs) on long-horizon tasks, testing their ability to plan, reason spatially, and explore in dynamic environments. Our benchmark reveals that while current models show some success on simpler tasks, they struggle with more complex, procedurally generated environments like NetHack, especially when vision-based decision-making is involved. We provide an open, fine-grained evaluation framework to drive progress in autonomous agent research. Read more about agent quest in our paper!
Citation
@inproceedings{
author2024AgentQuest,
title={AgentQuest: Benchmarking LLM and VLM Agents on Long-Horizon Interactive Tasks},
author={ANONYMOUS},
booktitle={pre-print},
year={2024},
url={https://example.com/AgentQuest}
}